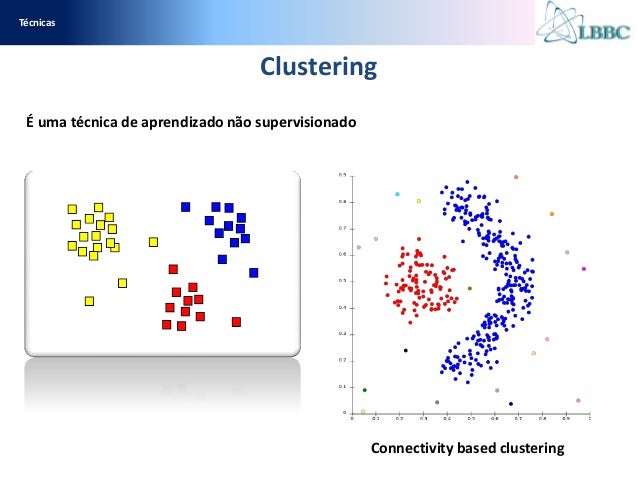
Em geral todos Machine Learning Algoritmos precisam ser treinados para tarefas de aprendizado supervisionado como classificação, previsão, etc., ou para tarefas de aprendizagem não supervisionada, como clustering.
Ao treinar isso significa treiná-los nas entradas particulares para que mais tarde possamos testá-los para as entradas desconhecidas (que nunca viu antes) para os quais eles podem classificar ou prever etc (no caso de aprendizagem supervisionada) com base na sua aprendizagem. Isto é o que a maioria das técnicas de Aprendizado de Máquina como redes neurais, SVM, Bayesian etc. são baseadas.
Assim, em um projeto geral Machine Learning, basicamente você tem que dividir seu conjunto de entrada a um conjunto de Desenvolvimento (Training Set + Dev-Test Set) e um conjunto de teste (ou conjunto de Avaliação). Lembre-se de seu objetivo básico seria que o sistema aprende e classifica novas entradas que nunca viu antes em qualquer Dev ou conjunto de teste.
O teste definir normalmente tem o mesmo formato que o conjunto de treinamento. No entanto, é muito importante que o conjunto de teste ser distinto do corpus formação: se simplesmente reutilizado na formação definido como o conjunto de teste, em seguida, um modelo que simplesmente memorizado sua entrada, sem aprender a generalizar para novos exemplos, receberia misleadingly notas altas.
Em geral, para um exemplo, pode ser de 70% a formação casos indicados. Lembre-se também para particionar o conjunto original para o treinamento e teste define aleatoriamente.
Para demonstrar o conceito de Naïve Bayes Classificação, considere o exemplo dado abaixo:
Conforme indicado, os objetos podem ser classificados como
verde ou
vermelho. Nossa tarefa é classificar novos casos que eles chegam, isto é, decidir qual rótulo de classe a que pertencem, com base nos objetos atualmente existentes.
Uma vez que existem duas vezes mais objetos
verde como
Vermelho, é razoável acreditar que um novo caso (o que não foi observado até o momento) é duas vezes mais propensos a ter a adesão
Verde em vez do
Vermelho. Na análise Bayesian, esta crença é conhecida como a probabilidade a priori. probabilidade a priori são baseadas na experiência anterior, neste caso, a percentagem de objetos
verde e
vermelho, e muitas vezes utilizado para prever resultados antes de realmente acontecer.
Assim, podemos escrever:
Probabilidade Prior do VERDE: número de objetos verdes
/ número total de objetos.
Probabilidade Prior do Vermelho: número de objetos vermelho
/ número total de objetos.
Uma vez que há um total de
60 objetos, dos quais
40 são
verdes e 20 RED, nossas probabilidade a priori para a adesão da classe são:
Probabilidade priori para
VERDE: 40/60
Probabilidade priori para
VERMELHO: 20/60
Tendo formulado nossa probabilidade a priori, agora estamos prontos para classificar um novo objeto (círculo branco no diagrama abaixo). Uma vez que os objectos são assim agrupados, é razoável assumir que o mais
VERDE (ou
vermelho) objetos na vizinhança de X, a mais provável que os novos casos pertencem a essa cor específica. Para medir essa probabilidade, traçamos um círculo em torno de X, que engloba um número (a ser escolhido a priori) de pontos, independentemente de seus rótulos de classe. Em seguida, calcular o número de pontos no círculo pertencentes a cada rótulo de classe. A partir disso, calcular a probabilidade:
A partir da ilustração acima, é claro que a Probabilidade de X dado
VERDE é menor do que Probabilidade de X dado
Vermelho, uma vez que o círculo abrange um objeto
VERDE e 3 os
vermelhos. Assim:
Embora as probabilidade a priori indicam que X pode pertencer a
VERDE (dado que existem duas vezes mais do
VERDE comparação com
Vermelha) a probabilidade indique o contrário; que os membros da classe de X é
Vermelha (dado que existem objetos mais vermelho nas proximidades de X do que
verde). Na análise Bayesian, a classificação final é produzido pela combinação de ambas as fontes de informação, isto é, a anterior e a probabilidade, para formar uma probabilidade posterior utilizando a chamada regra de Bayes (nome de Thomas Bayes Rev. 1702-1761).
Finalmente, classificamos X como o vermelho desde a sua adesão à classe atinge a maior probabilidade posterior.
Fonte:
statsoft, stackoverflow.