# Load dataset
url = "iris.data"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pandas.read_csv(url, names=names)
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
sábado, 24 de dezembro de 2016
terça-feira, 13 de dezembro de 2016
Visualizando uma Árvore de Decisão
import numpy as np from sklearn.datasets import load_iris from sklearn import tree iris = load_iris() test_idx = [0,50,100] # training data train_target = np.delete(iris.target, test_idx) #removido as amostras 0,50,100 train_data = np.delete(iris.data,test_idx, axis = 0) #removido as caracteristicas das amostras 0,50,100 # testing data test_target = iris.target[test_idx] #Amostra para testar test_data = iris.data[test_idx] #Dados para testar #print test_target #print test_data clf = tree.DecisionTreeClassifier() clf.fit(train_data, train_target) print test_target #imprime a label da amostra print clf.predict(test_data) #com base nos dados da amostrada passada, preve qual e a label #viz code from sklearn.externals.six import StringIO import pydotplus dot_data = StringIO() tree.export_graphviz(clf, out_file=dot_data, feature_names=iris.feature_names, class_names=iris.target_names, filled= True, rounded=True, impurity=False) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_pdf("iris.pdf")
Dataset Iris
from sklearn.datasets import load_iris
iris = load_iris() #Carrega o iris dataset como iris
print iris.feature_names #['sepal comprimento (cm)', 'sepal largura (cm)', #'petal comprimento (cm)', 'petal largura (cm)'
print iris.target_names #['setosa' 'versicolor' 'virginica'] ou [0,1,2]
print iris.data[0] #mostra as caracteristicas da primeira amostra, #que é [ 5.1 3.5 1.4 0.2]
print iris.target[0] #mostra qual é o tipo da primeira amostra, que é a setosa ou 0
for i in range(len(iris.target)):
print "Example %d: label %s, features %s" % (i, iris.target[i], iris.data[i]) #imprime o nº do exemplo, qual é o tipo da amostra e as #caracteriticas das amostras
terça-feira, 20 de setembro de 2016
Caffe Instalaçao
Ubuntu 16.04
Instalar dependencias com
e modifica para o local onde voce instalou, e edite o .bashrc que fica na sua pasta pessoal e add a seguinte linha de codigo
e salve. Agora no terminal
Edite o arquivo /etc/profile adicionando o
Agora teste no python
Instalar dependencias com
Dependencias de Python na pasta caffe/pythonsudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-devlibhdf5-serial-dev protobuf-compiler sudo apt-get install --no-install-recommends libboost-all-dev
Compilação e Instalaçaofor req in $(cat requirements.txt); do pip install $req; done
git clone https://github.com/BVLC/caffe.git
cd caffe
mkdir build
cd build
cmake ..
make all
make install
make runtest
e modifica para o local onde voce instalou, e edite o .bashrc que fica na sua pasta pessoal e add a seguinte linha de codigo
export PYTHONPATH=/home/seuusuario/caffe/python
e salve. Agora no terminal
source ~/.bashrcou para ser permanente
Edite o arquivo /etc/profile adicionando o
e salve.export PYTHONPATH=/home/seuusuario/caffe/python
Agora teste no python
import caffe
quarta-feira, 14 de setembro de 2016
Sklearn Naive Bayes GaussianNB Explicação
Exemplo:
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X, Y)
print(clf.predict([[-0.8, -1]]))
Tentarei explicar como funciona essas linhas de codigos, essas informaçoẽs pode estar errada
pois eu to tentando aprender agora o sklearn naive bayes.
Primeiro vamos fazer uma tabela com as informaçoes dos array.

Agora vamos tirar a media, e tambem tirar a variaçao.(Veja como tirar a variação)

Agora vamos testar o exemplo.

Se você não sabe como resolver esta questão, veja como resolver esse problema clicando Aqui.

P(1) = 3/6 = 0.5
P(A|1) = 0.194186054983
P(B|1) = 0.584909149172
P(Posterior) = 0.056790
Agora a do 2.
P(2) = 3/6 = 0.5
P(A|2) = 0.194186054983
P(B|2) = 0.000196213696897
P(Posterior) = 0.000019050
Entao podemos concluir que [-0.8,-1] é do tipo 1, pois 0.056790> 0.000019.
terça-feira, 13 de setembro de 2016
Naive Bayes Classificação
Classificação de gênero
Problema: classificar se uma determinada pessoa é um macho ou uma fêmea com base nas características medidas. As características incluem a altura, peso e tamanho do pé.
Treinamento
Exemplo formação definido abaixo.

O classificador criado a partir do conjunto de treinamento usando uma suposição distribuição Gaussiana seria (dadas as variações são variâncias amostrais imparciais):









Poderiamos fazer isto usando o sklearn.naive_bayes.GaussianNB
Fonte: https://en.wikipedia.org/wiki/Naive_Bayes_classifier
Problema: classificar se uma determinada pessoa é um macho ou uma fêmea com base nas características medidas. As características incluem a altura, peso e tamanho do pé.
Treinamento
Exemplo formação definido abaixo.

O classificador criado a partir do conjunto de treinamento usando uma suposição distribuição Gaussiana seria (dadas as variações são variâncias amostrais imparciais):

V. = Variação.
Como medir a variação
Desvio padrão de população
Desvio padrão de população



Ou Desvio padrão da amostra

Nossa média da amostra estava errado em 7%, e nossa Desvio Padrão da Amostra estava errado em 21%.

Nossa média da amostra estava errado em 7%, e nossa Desvio Padrão da Amostra estava errado em 21%.
Vamos dizer que temos classes equiprováveis de modo P (masculino) = P (feminino) = 4/8 =0,5. Esta distribuição de probabilidade prévia poderia ser baseados no nosso conhecimento de frequências na população maior, ou na frequência no conjunto de treinamento.
Testando
Abaixo está uma amostra a ser classificado como um macho ou fêmea.

Desejamos para determinar quais posterior é maior, do sexo masculino ou do sexo feminino. Para a classificação como macho posterior é dada por

Para a classificação como feminino posterior é dada por

A Evidence (também denominado constante de normalização) pode ser calculado:
No entanto, dada a amostra a evidência é uma constante e, portanto, escalas ambos os posteriors de forma igual. É, por conseguinte, não faz efeito em classificação e pode ser ignorado. Nós agora determinaremos a distribuição de probabilidade para o sexo da amostra.
P(Masculino)=0.5

Codigo em python
import math
x = input("Digite x ?")
u = input("Digite u ?")
o = input("Digite O ?")
Result = (1 / (math.sqrt(2*math.pi) *o)) * math.exp(-(math.pow(x-u,2)/(2*math.pow(o,2))))
print Result
Onde μ = 5.855 e σ = 0.162096 e x = 6 são os parâmetros de distribuição normal que tenham sido previamente determinados a partir do conjunto de treinamento. Note-se que um valor maior do que 1 é OK aqui - é uma densidade de probabilidade do que uma probabilidade, porque a altura é uma variável contínua.
P(Peso| Masculino) = 3.80206704017e-07=0,00000038
P(T.Pes| Masculino) = 0.000221871224731
Numerador posterior(Masculino) = 6.9539887e-11
P(Feminino)=0.5
P(Altura| Feminino) = 0.144231596331
P(Peso| Feminino) = 0.0193504591478
P(T.Pes| Feminino) =0.32286937325
Numerador posterior(Feminino) = 4,505557e-4
Dado que numerador posterior é maior no caso do sexo feminino, prevemos a amostra é fêmea.
Poderiamos fazer isto usando o sklearn.naive_bayes.GaussianNB
import numpy as np
X = np.array([[6, 180, 12], [5.92, 190,11], [5.58, 170, 12], [5.92,165, 10], [5, 100,6], [5.5, 150,8],[5.42, 130, 7],[5.75, 150, 9]])
Y = np.array([1, 1, 1, 1, 2, 2, 2, 2])
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X, Y)
print(clf.predict([[6, 130, 8]]))
Fonte: https://en.wikipedia.org/wiki/Naive_Bayes_classifier
domingo, 11 de setembro de 2016
Naive Bayes Frutas Exemplo
Vamos testá-lo em um exemplo para aumentar a nossa compreensão:
Vamos dizer que nós temos dados sobre 1000 peças de fruta. Eles serao banana, laranja ou algumas outras frutas. Sabemos 3 características sobre cada fruta:
 Podemos pré-computar um monte de coisas sobre a nossa coleção da fruta.
Podemos pré-computar um monte de coisas sobre a nossa coleção da fruta.
As chamadas "Prior" probabilidades. (Se não conhecia nenhum dos atributos de fruto, esta seria a nossa suposição.) Estas são as nossas taxas de base.
Digamos que nos são dadas as propriedades de uma fruta desconhecida, e pediu para classificá-lo. Somos informados de que o fruto é longo, doce e amarelo. É uma banana? É uma laranja? Ou é algum outro Fruit?
Podemos simplesmente executar os números para cada um dos 3 resultados, uma por uma. Em seguida, escolha a maior probabilidade e 'classificar' nosso fruto desconhecido como pertencendo à classe que teve a maior probabilidade com base em nossas provas antes (a nossa 1000 frutas conjunto de treinamento):


 Por uma margem esmagadora (0,969 >> 0,072), classificamos este / Long fruta doce / amarelo como provável que seja uma banana.
Por uma margem esmagadora (0,969 >> 0,072), classificamos este / Long fruta doce / amarelo como provável que seja uma banana.
Fonte: http://stackoverflow.com/questions/10059594/a-simple-explanation-of-naive-bayes-classification
Vamos dizer que nós temos dados sobre 1000 peças de fruta. Eles serao banana, laranja ou algumas outras frutas. Sabemos 3 características sobre cada fruta:
- Se é longo
- Se é doce e
- Se sua cor é amarela.

As chamadas "Prior" probabilidades. (Se não conhecia nenhum dos atributos de fruto, esta seria a nossa suposição.) Estas são as nossas taxas de base.
P(Banana) = 0.5 (500/1000)
P(Laranja) = 0.3 (300/1000)
P(Outras Fruitas) = 0.2 (200/1000)p(Longo) = 0.5 (500/1000)
P(Doce) = 0.65 (650/1000)
P(Amarelo) = 0.8 (800/1000)P(Longo|Banana) = 0.8 (400/500)
P(Longo|Laranja) = 0 (0/300)[Laranjas nunca estão longas no todas as frutas que temos visto.]
....
P(Amarelo|Outras Fruitas) = 50/200 = 0.25
P(Nao Amarelo|Outras Fruitas) = 150/200 = 0.75Digamos que nos são dadas as propriedades de uma fruta desconhecida, e pediu para classificá-lo. Somos informados de que o fruto é longo, doce e amarelo. É uma banana? É uma laranja? Ou é algum outro Fruit?
Podemos simplesmente executar os números para cada um dos 3 resultados, uma por uma. Em seguida, escolha a maior probabilidade e 'classificar' nosso fruto desconhecido como pertencendo à classe que teve a maior probabilidade com base em nossas provas antes (a nossa 1000 frutas conjunto de treinamento):



Fonte: http://stackoverflow.com/questions/10059594/a-simple-explanation-of-naive-bayes-classification
Uma Simples explicação do Naive Bayes Classificação
Em geral todos Machine Learning Algoritmos precisam ser treinados para tarefas de aprendizado supervisionado como classificação, previsão, etc., ou para tarefas de aprendizagem não supervisionada, como clustering.
Ao treinar isso significa treiná-los nas entradas particulares para que mais tarde possamos testá-los para as entradas desconhecidas (que nunca viu antes) para os quais eles podem classificar ou prever etc (no caso de aprendizagem supervisionada) com base na sua aprendizagem. Isto é o que a maioria das técnicas de Aprendizado de Máquina como redes neurais, SVM, Bayesian etc. são baseadas.
Assim, em um projeto geral Machine Learning, basicamente você tem que dividir seu conjunto de entrada a um conjunto de Desenvolvimento (Training Set + Dev-Test Set) e um conjunto de teste (ou conjunto de Avaliação). Lembre-se de seu objetivo básico seria que o sistema aprende e classifica novas entradas que nunca viu antes em qualquer Dev ou conjunto de teste.
O teste definir normalmente tem o mesmo formato que o conjunto de treinamento. No entanto, é muito importante que o conjunto de teste ser distinto do corpus formação: se simplesmente reutilizado na formação definido como o conjunto de teste, em seguida, um modelo que simplesmente memorizado sua entrada, sem aprender a generalizar para novos exemplos, receberia misleadingly notas altas.
Em geral, para um exemplo, pode ser de 70% a formação casos indicados. Lembre-se também para particionar o conjunto original para o treinamento e teste define aleatoriamente.
Para demonstrar o conceito de Naïve Bayes Classificação, considere o exemplo dado abaixo:
 Conforme indicado, os objetos podem ser classificados como verde ou vermelho. Nossa tarefa é classificar novos casos que eles chegam, isto é, decidir qual rótulo de classe a que pertencem, com base nos objetos atualmente existentes.
Conforme indicado, os objetos podem ser classificados como verde ou vermelho. Nossa tarefa é classificar novos casos que eles chegam, isto é, decidir qual rótulo de classe a que pertencem, com base nos objetos atualmente existentes.
Uma vez que existem duas vezes mais objetos verde como Vermelho, é razoável acreditar que um novo caso (o que não foi observado até o momento) é duas vezes mais propensos a ter a adesão Verde em vez do Vermelho. Na análise Bayesian, esta crença é conhecida como a probabilidade a priori. probabilidade a priori são baseadas na experiência anterior, neste caso, a percentagem de objetos verde e vermelho, e muitas vezes utilizado para prever resultados antes de realmente acontecer.
Assim, podemos escrever:
Probabilidade Prior do VERDE: número de objetos verdes / número total de objetos.
Probabilidade Prior do Vermelho: número de objetos vermelho / número total de objetos.
Uma vez que há um total de 60 objetos, dos quais 40 são verdes e 20 RED, nossas probabilidade a priori para a adesão da classe são:
Probabilidade priori para VERDE: 40/60
Probabilidade priori para VERMELHO: 20/60
Tendo formulado nossa probabilidade a priori, agora estamos prontos para classificar um novo objeto (círculo branco no diagrama abaixo). Uma vez que os objectos são assim agrupados, é razoável assumir que o mais VERDE (ou vermelho) objetos na vizinhança de X, a mais provável que os novos casos pertencem a essa cor específica. Para medir essa probabilidade, traçamos um círculo em torno de X, que engloba um número (a ser escolhido a priori) de pontos, independentemente de seus rótulos de classe. Em seguida, calcular o número de pontos no círculo pertencentes a cada rótulo de classe. A partir disso, calcular a probabilidade:


A partir da ilustração acima, é claro que a Probabilidade de X dado VERDE é menor do que Probabilidade de X dado Vermelho, uma vez que o círculo abrange um objeto VERDE e 3 os vermelhos. Assim:


Embora as probabilidade a priori indicam que X pode pertencer a VERDE (dado que existem duas vezes mais do VERDE comparação com Vermelha) a probabilidade indique o contrário; que os membros da classe de X é Vermelha (dado que existem objetos mais vermelho nas proximidades de X do que verde). Na análise Bayesian, a classificação final é produzido pela combinação de ambas as fontes de informação, isto é, a anterior e a probabilidade, para formar uma probabilidade posterior utilizando a chamada regra de Bayes (nome de Thomas Bayes Rev. 1702-1761).

Fonte: statsoft, stackoverflow.
Ao treinar isso significa treiná-los nas entradas particulares para que mais tarde possamos testá-los para as entradas desconhecidas (que nunca viu antes) para os quais eles podem classificar ou prever etc (no caso de aprendizagem supervisionada) com base na sua aprendizagem. Isto é o que a maioria das técnicas de Aprendizado de Máquina como redes neurais, SVM, Bayesian etc. são baseadas.
Assim, em um projeto geral Machine Learning, basicamente você tem que dividir seu conjunto de entrada a um conjunto de Desenvolvimento (Training Set + Dev-Test Set) e um conjunto de teste (ou conjunto de Avaliação). Lembre-se de seu objetivo básico seria que o sistema aprende e classifica novas entradas que nunca viu antes em qualquer Dev ou conjunto de teste.
O teste definir normalmente tem o mesmo formato que o conjunto de treinamento. No entanto, é muito importante que o conjunto de teste ser distinto do corpus formação: se simplesmente reutilizado na formação definido como o conjunto de teste, em seguida, um modelo que simplesmente memorizado sua entrada, sem aprender a generalizar para novos exemplos, receberia misleadingly notas altas.
Em geral, para um exemplo, pode ser de 70% a formação casos indicados. Lembre-se também para particionar o conjunto original para o treinamento e teste define aleatoriamente.
Para demonstrar o conceito de Naïve Bayes Classificação, considere o exemplo dado abaixo:
Uma vez que existem duas vezes mais objetos verde como Vermelho, é razoável acreditar que um novo caso (o que não foi observado até o momento) é duas vezes mais propensos a ter a adesão Verde em vez do Vermelho. Na análise Bayesian, esta crença é conhecida como a probabilidade a priori. probabilidade a priori são baseadas na experiência anterior, neste caso, a percentagem de objetos verde e vermelho, e muitas vezes utilizado para prever resultados antes de realmente acontecer.
Assim, podemos escrever:
Probabilidade Prior do VERDE: número de objetos verdes / número total de objetos.
Probabilidade Prior do Vermelho: número de objetos vermelho / número total de objetos.
Uma vez que há um total de 60 objetos, dos quais 40 são verdes e 20 RED, nossas probabilidade a priori para a adesão da classe são:
Probabilidade priori para VERDE: 40/60
Probabilidade priori para VERMELHO: 20/60
Tendo formulado nossa probabilidade a priori, agora estamos prontos para classificar um novo objeto (círculo branco no diagrama abaixo). Uma vez que os objectos são assim agrupados, é razoável assumir que o mais VERDE (ou vermelho) objetos na vizinhança de X, a mais provável que os novos casos pertencem a essa cor específica. Para medir essa probabilidade, traçamos um círculo em torno de X, que engloba um número (a ser escolhido a priori) de pontos, independentemente de seus rótulos de classe. Em seguida, calcular o número de pontos no círculo pertencentes a cada rótulo de classe. A partir disso, calcular a probabilidade:


A partir da ilustração acima, é claro que a Probabilidade de X dado VERDE é menor do que Probabilidade de X dado Vermelho, uma vez que o círculo abrange um objeto VERDE e 3 os vermelhos. Assim:



Finalmente, classificamos X como o vermelho desde a sua adesão à classe atinge a maior probabilidade posterior.
Fonte: statsoft, stackoverflow.
sábado, 10 de setembro de 2016
6 Passos Fáceis para Aprender o Algoritmo Naive Bayes (com o código em Python)
Introdução
Aqui está uma situação que você está:
Você está trabalhando em um problema de classificação e você gerou o seu conjunto de hipóteses, criou características e discuti a importância de variáveis. Dentro de uma hora, as partes interessadas querem ver o primeiro corte do modelo.
O que você vai fazer? Você tem hunderds de milhares de pontos de dados e algumas variáveis no conjunto de dados de treinamento. Em tal situação, se estivesse em seu lugar, eu teria usado 'Naive Bayes', que pode ser extremamente rápido em relação a outros algoritmos de classificação. Ele funciona em teorema de Bayes de probabilidade para prever a classe de conjunto de dados desconhecido.
Neste artigo, vou explicar o básico deste algoritmo, para que da próxima vez que você se deparar com grandes conjuntos de dados, você pode trazer este algoritmo para a ação.
Índice:
O que é o algoritmo Naive Bayes?
É uma técnica de classificação baseado no teorema de Bayes com uma suposição de independência entre os preditores. Em termos simples, um classificador Naive Bayes assume que a presença de uma característica particular, uma classe não está relacionada com a presença de qualquer outro recurso. Por exemplo, um fruto pode ser considerado como uma maçã se é vermelho, redondo, e cerca de 3 polegadas de diâmetro. Mesmo que esses recursos dependem uns dos outros ou sobre a existência de outras características, todas estas propriedades contribuem de forma independente para a probabilidade de que este fruto é uma maçã e é por isso que é conhecido como 'Naive'.
modelo Naive Bayes é fácil de construir e particularmente útil para grandes conjuntos de dados. Junto com simplicidade, Naive Bayes é conhecido por superar métodos de classificação mesmo altamente sofisticados.
Teorema de Bayes fornece uma forma de calcular a probabilidade posterior P (C | X) a partir de P (C), P (x) e P (X | c). Olhe para a equação abaixo:

Acima,
P(c|x) é a probabilidade posterior da classe (c, alvo) dada preditor (x, atributos).
P(c) é a probabilidade prior de classe.
P(x|c) é a probabilidade que representa a probabilidade de preditor dada classe.
P(x) é a probabilidade prior de preditor.
Como o Algoritmo Naive Bayes funciona?
Vamos entender isso usando um exemplo. Abaixo eu tenho um conjunto de dados de treinamento do tempo e do destino da variável 'Play' correspondente (sugerindo possibilidades de jogar). Agora, precisamos classificar se os jogadores vão jogar ou não com base na condição do tempo. Vamos seguir os passos abaixo para realizar a operação.
Passo 1: Converter o conjunto de dados em uma tabela de frequência
Passo 2: Criar tabela de Probabilidade de encontrar as probabilidades como probabilidade Nublado = 0,29 e probabilidade de jogar é 0,64.

Passo 3: Agora, usar a equação Naive Bayesian para calcular a probabilidade posterior para cada classe. A classe com maior probabilidade posterior é o resultado de previsão.
Problema: Os jogadores irão jogar se o tempo está ensolarado. É esta afirmação está correta?
Podemos resolver isso usando acima método discutido de probabilidade posterior.
Probabilidade de jogar no sol.

Probabilidade de jogar Nublado
Probabilidade de jogar na Chuva
Aplicações de Naive Bayes Algoritmos
Como construir um modelo básico usando Naive Bayes em Python?
Mais uma vez, scikit learn (biblioteca python) vai ajudar construir um modelo Naive Bayes em Python. Existem três tipos de modelo Naive Bayes sob o scikit learn biblioteca:
Gaussian: É usado na classificação e assume que as características seguem uma distribuição normal.
Multinomial: É usado para a contagem discretos. Por exemplo, vamos dizer, nós temos um problema de classificação de texto. Aqui podemos considerar tentativas de Bernoulli, que é um passo além e, em vez de "palavra que ocorre no documento", temos "contar quantas vezes a palavra ocorre no documento", você pode pensar nisso como "número de vezes que o número desfecho x_i é observado durante os ensaios n ".
Bernoulli: O modelo binomial é útil se os vetores de características são binários (ou seja zeros e uns). Uma aplicação seria de classificação de texto com 'saco de palavras' modelo onde os 1s e 0s são "palavra ocorre no documento" e "palavra não ocorre no documento", respectivamente.
Com base no seu conjunto de dados, você pode escolher qualquer um modelo acima discutidos. Abaixo está o exemplo de modelo de Gaussian.
Fonte
Aqui está uma situação que você está:
Você está trabalhando em um problema de classificação e você gerou o seu conjunto de hipóteses, criou características e discuti a importância de variáveis. Dentro de uma hora, as partes interessadas querem ver o primeiro corte do modelo.
O que você vai fazer? Você tem hunderds de milhares de pontos de dados e algumas variáveis no conjunto de dados de treinamento. Em tal situação, se estivesse em seu lugar, eu teria usado 'Naive Bayes', que pode ser extremamente rápido em relação a outros algoritmos de classificação. Ele funciona em teorema de Bayes de probabilidade para prever a classe de conjunto de dados desconhecido.
Neste artigo, vou explicar o básico deste algoritmo, para que da próxima vez que você se deparar com grandes conjuntos de dados, você pode trazer este algoritmo para a ação.
Índice:
- O que é algoritmo Naive Bayes?
- Como o Algoritmo Naive Bayes funciona?
- Quais são os Prós e Contras do uso de Naive Bayes?
- 4 Aplicações do Algoritmo Naive Bayes
- Passos para construir um modelo Naive Bayes básico em Python
- Dicas para melhorar a força do modelo Naive Bayes
O que é o algoritmo Naive Bayes?
É uma técnica de classificação baseado no teorema de Bayes com uma suposição de independência entre os preditores. Em termos simples, um classificador Naive Bayes assume que a presença de uma característica particular, uma classe não está relacionada com a presença de qualquer outro recurso. Por exemplo, um fruto pode ser considerado como uma maçã se é vermelho, redondo, e cerca de 3 polegadas de diâmetro. Mesmo que esses recursos dependem uns dos outros ou sobre a existência de outras características, todas estas propriedades contribuem de forma independente para a probabilidade de que este fruto é uma maçã e é por isso que é conhecido como 'Naive'.
modelo Naive Bayes é fácil de construir e particularmente útil para grandes conjuntos de dados. Junto com simplicidade, Naive Bayes é conhecido por superar métodos de classificação mesmo altamente sofisticados.
Teorema de Bayes fornece uma forma de calcular a probabilidade posterior P (C | X) a partir de P (C), P (x) e P (X | c). Olhe para a equação abaixo:

Acima,
P(c|x) é a probabilidade posterior da classe (c, alvo) dada preditor (x, atributos).
P(c) é a probabilidade prior de classe.
P(x|c) é a probabilidade que representa a probabilidade de preditor dada classe.
P(x) é a probabilidade prior de preditor.
Como o Algoritmo Naive Bayes funciona?
Vamos entender isso usando um exemplo. Abaixo eu tenho um conjunto de dados de treinamento do tempo e do destino da variável 'Play' correspondente (sugerindo possibilidades de jogar). Agora, precisamos classificar se os jogadores vão jogar ou não com base na condição do tempo. Vamos seguir os passos abaixo para realizar a operação.
Passo 1: Converter o conjunto de dados em uma tabela de frequência
Passo 2: Criar tabela de Probabilidade de encontrar as probabilidades como probabilidade Nublado = 0,29 e probabilidade de jogar é 0,64.

Passo 3: Agora, usar a equação Naive Bayesian para calcular a probabilidade posterior para cada classe. A classe com maior probabilidade posterior é o resultado de previsão.
Problema: Os jogadores irão jogar se o tempo está ensolarado. É esta afirmação está correta?
Podemos resolver isso usando acima método discutido de probabilidade posterior.
Probabilidade de jogar no sol.

Probabilidade de jogar Nublado
P(Sim | Nublado) = P( Nublado | Sim) * P(Sim) / P (Nublado)
P(Nublado |Sim) = 4/9 = 0.44
P( Sim)= 9/14 = 0.64
P(Nublado) = 4/14 = 0.29
P (Sim | Nublado) = 0.44 * 0.64 / 0.29 =0,97
Probabilidade de jogar na Chuva
P(Sim | Chuva) = P( Chuva | Sim) * P(Sim) / P (Chuva)
P(Chuva |Sim) = 2/9 = 0.22
P( Sim)= 9/14 = 0.64
P(Chuva) = 5/14 = 0.36Naive Bayes usa um método similar para prever a probabilidade de classe diferente com base em vários atributos. Este algoritmo é usado principalmente em classificação de texto e com os problemas que têm múltiplas classes.
P (Sim | Chuva) = 0.22 * 0.64 / 0.36 =0,39
Aplicações de Naive Bayes Algoritmos
- Previsão em tempo real: Naive Bayes é um classificador de aprendizagem ansiosa e é certo rapidamente. Assim, ela pode ser usada para fazer previsões em tempo real.
- Multi classe Previsão : Este algoritmo também é conhecida por multi critério de previsão de classe. Aqui podemos prever a probabilidade de múltiplas classes de variável-alvo.
- Classificação de textos / Filtragem de spam / Análise de sentimento: Naive Bayes classificadores utilizados principalmente em classificação de textos (devido a um melhor resultado em problemas de classe múltiplas e regra independência) têm maior taxa de sucesso em comparação com outros algoritmos. Como resultado, ele é amplamente utilizado na filtragem de spam (identificar spam e-mail) e Sentiment Analysis (em análise de mídia social, para identificar sentimentos positivos e negativos dos clientes)
- Recomendação Sistema: Naive Bayes classificador e filtragem colaborativa em conjunto constrói um sistema de recomendação que utiliza técnicas de aprendizado de máquina e mineração de dados para filtrar a informação invisível e prever se um usuário gostaria de um determinado recurso ou não.
Como construir um modelo básico usando Naive Bayes em Python?
Mais uma vez, scikit learn (biblioteca python) vai ajudar construir um modelo Naive Bayes em Python. Existem três tipos de modelo Naive Bayes sob o scikit learn biblioteca:
Gaussian: É usado na classificação e assume que as características seguem uma distribuição normal.
Multinomial: É usado para a contagem discretos. Por exemplo, vamos dizer, nós temos um problema de classificação de texto. Aqui podemos considerar tentativas de Bernoulli, que é um passo além e, em vez de "palavra que ocorre no documento", temos "contar quantas vezes a palavra ocorre no documento", você pode pensar nisso como "número de vezes que o número desfecho x_i é observado durante os ensaios n ".
Bernoulli: O modelo binomial é útil se os vetores de características são binários (ou seja zeros e uns). Uma aplicação seria de classificação de texto com 'saco de palavras' modelo onde os 1s e 0s são "palavra ocorre no documento" e "palavra não ocorre no documento", respectivamente.
Com base no seu conjunto de dados, você pode escolher qualquer um modelo acima discutidos. Abaixo está o exemplo de modelo de Gaussian.
Fonte
Aprendizado de Máquina: A definição problema
Em geral, um problema de aprendizagem considera um conjunto de nº amostras de dados e, em seguida, tenta prever propriedades de dados desconhecidos. Se cada uma das amostras é mais do que um único número e, por exemplo, uma entrada de multi-dimensional (aka dados multivariados), que se diz ter características ou vários atributos.
Podemos separar problemas de aprendizagem em algumas grandes categorias:
Aprendizado Supervisionado, no qual os dados vem com atributos adicionais que queremos prever. Este problema pode ser:
Classificação: amostras pertencem a duas ou mais classes e queremos aprender com dados já rotulados como prever a classe de dados não marcados. Um exemplo do problema de classificação que seria exemplo reconhecimento dígitos escrita à mão, em que o objectivo consiste em atribuir a cada vector de entrada para um de um número finito de categorias discretas. Outra maneira de pensar de classificação é como uma discreta (em oposição a contínua) forma de aprendizagem supervisionada, onde se tem um número limitado de categorias e para cada uma das amostras n fornecidos, um é tentar classificá-los com a categoria correcta ou classe .




A resposta seria classe com xifre: Bufalo e Veado.
classe sem xifre: Cavolo e gato.
Regressão: se a saída desejada é constituída por uma ou mais variáveis contínuas, em seguida, a tarefa é chamado de regressão. Um exemplo de um problema de regressão seria a previsão do comprimento de um salmão como uma função da sua idade e peso.

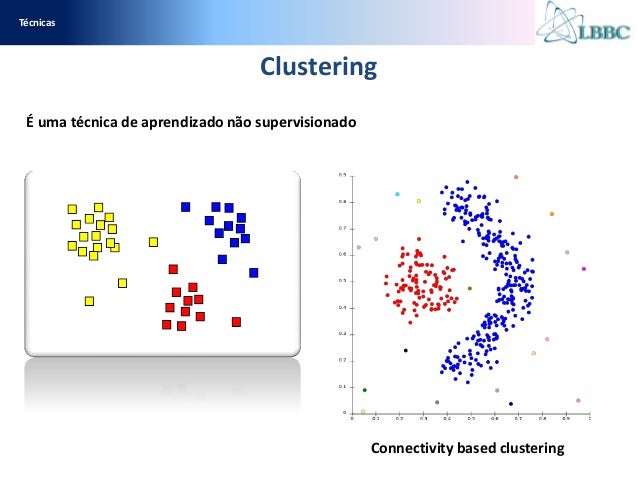
Aprendizado não supervisionado, no qual os dados de treinamento consiste em um conjunto de vetores de entrada x sem quaisquer valores-alvo correspondentes. O objetivo em tais problemas podem ser descobrir grupos de exemplos semelhantes dentro dos dados, onde é chamado de agrupamento, ou para determinar a distribuição de dados dentro do espaço de entrada, conhecida como uma estimativa da densidade, ou para projectar os dados de um de alta dimensional espaço para baixo para duas ou três dimensões para fins de visualização.
Conjunto de Treinamento e Conjunto de Teste
Aprendizagem de Máquina é sobre aprender algumas propriedades de um conjunto de dados e aplicá-las com novos dados. É por isso que uma prática comum na aprendizagem de máquina para avaliar um algoritmo é dividir os dados em mãos em dois conjuntos, um que nós chamamos o conjunto de treinamento em que aprendemos propriedades de dados e um que nós chamamos de ensaios apresentadas em que testamos estes propriedades.
Aprendizagem de Máquina é sobre aprender algumas propriedades de um conjunto de dados e aplicá-las com novos dados. É por isso que uma prática comum na aprendizagem de máquina para avaliar um algoritmo é dividir os dados em mãos em dois conjuntos, um que nós chamamos o conjunto de treinamento em que aprendemos propriedades de dados e um que nós chamamos de ensaios apresentadas em que testamos estes propriedades.
quinta-feira, 8 de setembro de 2016
Assinar:
Comentários (Atom)